Loading TerraMind research...
TerraMind
Geospatial Foundation Model for Earth Observation
Research Papers & Documentation
This research includes two complementary papers: TerraMind describes the large-scale generative foundation model, while TerraMesh details the planetary-scale multimodal dataset used for training the model.
TerraMind: Large-Scale Generative Multimodality for Earth Observation
Main research paper describing the TerraMind foundation model architecture and capabilities
TerraMesh: A Planetary Mosaic of Multimodal Earth Observation Data
Dataset paper describing the multimodal Earth observation data used for training TerraMind
TerraMind Architecture Analysis
Model Structure from Research Paper
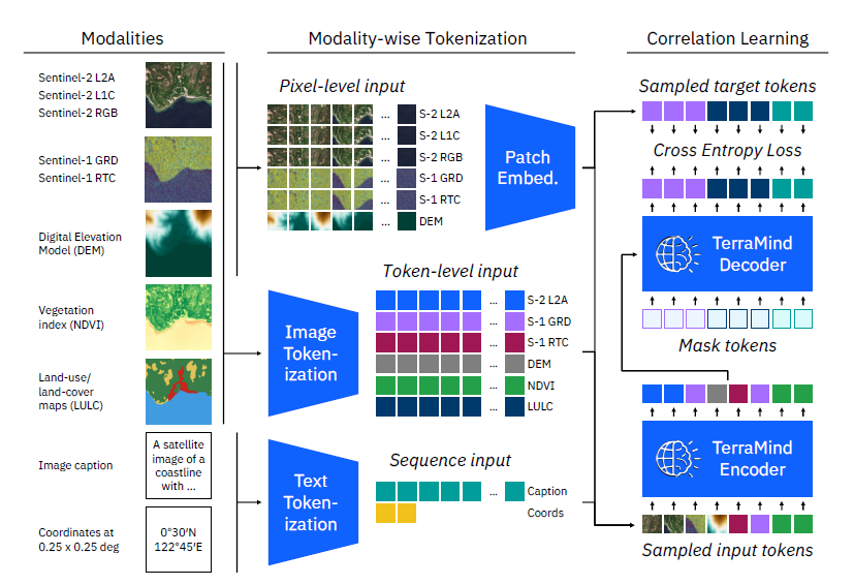
TerraMind Model Structure: Complete pipeline from modalities to correlation learning
Architecture Components
- Input Modalities: Sentinel-2 (L2A, L1C, RGB), Sentinel-1 (GRD, RTC), DEM, NDVI, LULC
- Tokenization: Modality-wise tokenization with pixel-level and token-level input processing
- Core Processing: Patch embedding, image tokenization, and text tokenization
- Learning: Correlation learning with cross entropy loss and TerraMind encoder/decoder
How TerraMind Works:
TerraMind employs a sophisticated multi-modal transformer architecture that processes various Earth observation data types simultaneously. The model begins by ingesting multiple satellite data modalities including Sentinel-2 optical imagery, Sentinel-1 radar data, digital elevation models (DEM), vegetation indices (NDVI), and land use/land cover (LULC) classifications.
Each input modality undergoes specialized tokenization processes. Pixel-level inputs are converted into patch embeddings, while sequence data is processed through text tokenization. This unified tokenization approach allows the model to handle heterogeneous geospatial data within a single transformer framework.
The core TerraMind encoder-decoder architecture then performs correlation learning, identifying spatial and temporal relationships across different data modalities. This enables the model to generate high-quality synthetic satellite imagery, perform cross-modal translation, and extract meaningful geospatial insights through its foundation model capabilities.
Foundation Model Overview

Key Components: Multi-modal input processing, foundation model core, and any-modality output generation
Detailed Architecture Analysis

Analysis Focus: Dual-scale transformer processing, token-level context, and pixel-level precision mechanisms
Data Analysis & Generation Examples
Sentinel-2 Optical Image

Sensor: Sentinel-2 L2A satellite optical data
Resolution: 10 meters per pixel
Coverage: 224×224 pixel area (2.24 km × 2.24 km)
Generated Radar Data
.png)
Type: S1GRD - Synthetic Aperture Radar
Shows: Surface roughness and texture correlations
Capability: All-weather, cloud penetration
Generated Digital Elevation
.png)
Type: DEM - 3D height information
Shows: Elevation changes and topographic variations
Use: Water flow and landslide risk analysis
Generated Land Use/Cover
.png)
Classification: ESRI classes with sharp boundaries
Colors: Green=Forest/Trees, Blue=Water, Orange=Bare ground
Generation: High semantic accuracy automated classification
Performance Analysis: Sentinel-2 vs Generated Data

Key Findings
- • High fidelity in spectral reproduction
- • Consistent spatial resolution quality
- • Effective cloud and shadow handling
- • Preserved geospatial accuracy
Research Impact
This comparison validates TerraMind's capability to generate high-quality satellite imagery data that maintains the spectral and spatial characteristics of real Sentinel-2 observations.
Research Session Documentation
Research Session Analysis

Research session documentation from September 16, 2025
Extended Analysis Session

Extended analysis session and methodology development
Additional Research Analysis
Thinking-in-Modalities Framework
Framework Analysis: TerraMind's approach to cross-modal understanding and generation capabilities
Additional Analysis Images
Space reserved for future research documentation
Research Documentation Status
Research Methodology: This comprehensive analysis incorporates two official IBM Research papers: TerraMind (the large-scale generative foundation model for Earth observation) and TerraMesh (the planetary mosaic dataset used for training). The documentation includes detailed architecture diagrams, performance comparison studies, and practical implementation examples demonstrating TerraMind's advanced multi-modal capabilities and real-world applications in geospatial intelligence. All analysis is validated through comparative studies with Sentinel-2 satellite data and based on actual research findings.